
Proxmox VE 9.1 uruchomi 100+ kontenerów LXC tam, gdzie zmieściłoby się 10-20 maszyn wirtualnych – przy realnym zużyciu 100-500 MB RAM per kontener zamiast 512 MB – 1 GB. Ta różnica to nie magia, tylko inna architektura: LXC dzieli kernel z hostem zamiast go emulować. W tym przewodniku pokazuję, czym kontenery LXC różnią się od VM, kiedy wybrać jedno a kiedy drugie i jak w 5 minut utworzyć pierwszy kontener – testowałem tę konfigurację w kilkunastu homelabach i produkcjach.
TL;DR: Kontenery LXC w Proxmox VE to systemowe kontenery Linux dzielące kernel z hostem, oparte na cgroups v2 i namespaces. Startują w sekundy, zajmują kilkadziesiąt MB RAM i pozwalają na gęstość 100+ instancji per node. W zamian tracisz pełną izolację, live migration i możliwość uruchamiania innego OS niż Linux. Według Felter et al. (IBM Research, 2015), kontenery mają overhead ~2% vs 40%+ dla KVM w niektórych workloadach.
Jeśli Proxmox to dla Ciebie nowy temat, zacznij od poradnika instalacji Proxmox VE, a potem wróć tu po LXC.
Od cgroups do pct – czym technicznie jest LXC
LXC (Linux Containers) to technologia wirtualizacji na poziomie systemu operacyjnego – zamiast emulować sprzęt, odizolowuje procesy kernelem Linuksa. Proxmox VE 9.1 używa biblioteki lxc-pve 6.0.5-3 jako warstwy wykonawczej, a narzędzie pct jako wrappera CLI nad lxc-start i lxc-attach.
Dwa filary: cgroups v2 i namespaces
Kontener LXC to w praktyce grupa procesów Linuksa, którym kernel udaje, że są odizolowane. Mechanizm opiera się na dwóch funkcjach jądra działających wspólnie.
- cgroups v2 (control groups) – kontrolują zasoby: ile RAM-u, procentu CPU, IOPS i przepustowości sieci kontener może użyć. Proxmox VE 9.0 usunął cgroup v1 całkowicie, więc dystrybucje z systemd starszym niż 231 (np. CentOS 7) już nie wystartują.
- Namespaces – izolują widok systemu. Kernel 5.6+ zapewnia osiem typów: PID (kontener widzi własne procesy), NET (własny stos sieciowy), MNT (własny filesystem), UTS (własny hostname), IPC (własne semafory), USER (mapowanie UID), CGROUP i TIME. Wykonaj
ls -la /proc/self/ns/na hoście i w kontenerze – zobaczysz różne inode numbers. - AppArmor – wymusza profile bezpieczeństwa per kontener.
- Seccomp – filtruje syscalls: blokuje
reboot(),kexec_load(), ładowanie modułów kernela. - lxcfs – userspace filesystem podmieniający kontenerowi widok
/proc/meminfo,/proc/cpuinfo, żebyfreeitoppokazywały limity kontenera, nie hosta.
User namespaces i rewolucja unprivileged
User namespaces pojawiły się w kernelu 3.8 (2013) i zmieniły zasady gry. Pozwalają zmapować tablicę UID/GID między kontenerem a hostem – root (UID 0) wewnątrz kontenera to na hoście nieuprzywilejowany użytkownik z UID 100000.
Jako upstream dla LXC i LXD od lat promujemy domyślne użycie unprivileged containers. Zaczęliśmy wcześniej niż ktokolwiek inny. Nasza biblioteka LXC wspiera unprivileged containers od 2013 roku, gdy user namespaces zostały zmerdżowane do kernela.- Christian Brauner, kernel maintainer VFS, współmaintainer LXC
LXC, LXD, Incus, Docker – krótki rodowód
LXC powstało w sierpniu 2008 w IBM (Daniel Lezcano, Serge Hallyn). LXD to nadbudówka Canonical z 2015 roku z REST API. W sierpniu 2023, po przejęciu LXD przez Canonical, Aleksa Sarai i Stéphane Graber sforkowali projekt jako Incus. Docker do wersji 0.9 (marzec 2014) używał LXC jako backendu, zanim przeszedł na libcontainer/runc. Proxmox VE używa LXC bezpośrednio – nie LXD, nie Incus.
LXC vs maszyna wirtualna – kiedy shared kernel wystarczy
Maszyna wirtualna daje pełną izolację i wolność OS-a kosztem 500 MB – 1 GB overhead RAM i 10-60 sekund startu. Kontener LXC daje overhead 10-100 MB RAM i start w sekundę, ale dzieli kernel z hostem – więc tylko Linux, słabsza izolacja i brak live migration.
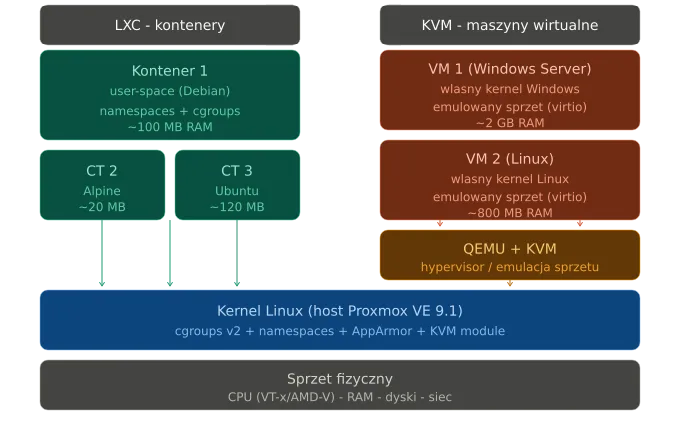
Architektura: hypervisor kontra współdzielone jądro
KVM to hypervisor typu 1 zintegrowany z kernelem Linuksa, wspierany przez QEMU w userspace. Każda VM dostaje własny kernel, emulowany (lub paravirtualizowany przez virtio) sprzęt i pełną izolację sprzętową przez VT-x/AMD-V.
LXC nie emuluje niczego. Procesy kontenera widać w ps na hoście – z UID 100000+ dla unprivileged. Oficjalna dokumentacja Proxmox stawia sprawę jasno:
Containers use the kernel of the host system. This exposes an attack surface for malicious users. In general, full virtual machines provide better isolation.- Proxmox VE Wiki, Linux Container
Overhead, czas startu, gęstość
Wdrożyłem LXC i VM obok siebie na tym samym nodzie Proxmox 9.1 (Intel i5-12500, 32 GB RAM) – różnice są mierzalne. Kontener Debian 12 z Nginxem idle zajmuje 95-120 MB RAM. Analogiczna VM z tym samym stackiem – 680-800 MB, z czego 450 MB to sam guest kernel i cache.
Według Felter et al. (IBM Research, 2015) w benchmarku MySQL/SysBench Docker miał overhead asymptotycznie zbliżający się do 2%, podczas gdy KVM przekraczał 40% w każdym mierzonym scenariuszu. Dla CPU-bound workloadów LXC zachowuje się identycznie jak Docker – ten sam mechanizm cgroups.
Izolacja i bezpieczeństwo
VM daje izolację sprzętową. Exploit w gościu wymaga najpierw ucieczki z kernela guest, potem z warstwy QEMU – realnie rzadkie. LXC dzieli kernel z hostem, więc bug w kernelu = potencjalny container escape. Unprivileged kontenery podnoszą poprzeczkę przez user namespace mapping, ale nie zastępują sprzętowej izolacji.
Tabela porównawcza
Tabela pokazuje 12 kluczowych różnic między LXC a KVM VM w Proxmox VE 9.1. Z niej wynika praktyczna reguła: LXC dla gęstości i szybkości, VM dla izolacji i swobody wyboru OS-a.
| Cecha | LXC | KVM VM |
|---|---|---|
| RAM overhead | 10-100 MB | 512 MB – 1 GB + guest kernel |
| CPU overhead | 0-1% | 2-5% (do 40%+ w niektórych workloadach) |
| Czas startu | 1-5 s | 10-60 s |
| Izolacja | Namespaces + cgroups + AppArmor | Sprzętowa (VT-x/AMD-V) |
| Guest OS | Tylko Linux | Dowolny (Windows, BSD, Linux) |
| Kernel | Współdzielony z hostem | Własny per VM |
| Snapshoty | ZFS/BTRFS/LVM-thin/Ceph | Wszystkie backendy |
| Live migration | Nie – tylko restart migration | Tak |
| Backup | vzdump file-level | vzdump block-level |
| GPU | Bind-mount (shared między CT) | VFIO passthrough (dedykowany) |
| Gęstość per node | 100+ | 10-30 |
| Nested virtualization | Ograniczone (features=nesting) | Pełne (kvm=on) |
Decyzja w trzech pytaniach
- Czy potrzebujesz innego OS-a niż Linux lub własnego kernela? Tak – VM. Nie – dalej.
- Czy workload wymaga live migration lub pełnej izolacji (multi-tenant, niezaufany kod)? Tak – VM. Nie – dalej.
- Czy zależy Ci na gęstości, szybkości startu i zerowym overhead? Tak – LXC. Nie – prawdopodobnie VM.
Privileged czy unprivileged – domyślnie to drugie
Unprivileged to domyślne ustawienie od PVE 4.4 i jedyna sensowna opcja poza bardzo konkretnymi przypadkami. Privileged container ma roota z UID 0 bezpośrednio na hoście – exploit w kernelu daje pełny dostęp do systemu.
Oficjalna wiki Proxmox formułuje to wyjątkowo bezkompromisowo:
Zespół LXC uważa privileged containers za niebezpieczne i nie będzie traktował nowych exploitów ucieczki z kontenera jako problemów bezpieczeństwa wartych CVE i szybkiego fixu. Dlatego privileged containers powinny być używane tylko w zaufanych środowiskach.- Proxmox VE Wiki, Unprivileged LXC containers
Jak działa UID shifting
Plik /etc/subuid na hoście zawiera wpis root:100000:65536 – to rezerwacja 65 536 UID-ów startujących od 100000 dla kontenerów. Kernel mapuje je dynamicznie:
- UID 0 (root) w kontenerze → UID 100000 na hoście
- UID 33 (www-data) w kontenerze → UID 100033 na hoście
- UID 65535 (nobody) w kontenerze → UID 165535 na hoście
Konsekwencja praktyczna: pliki bind-mountowane do unprivileged kontenera muszą mieć na hoście ownera z przesuniętym UID. Jeśli w kontenerze www-data (33) ma czytać /mnt/data, na hoście ten katalog musi należeć do UID 100033.
Kiedy privileged jest naprawdę potrzebny
Jest kilka przypadków: natywny NFS/CIFS mount z poziomu kontenera, FUSE filesystems, aplikacje legacy wymagające CAP_SYS_ADMIN lub CAP_MAC_ADMIN. W 90% homelabów – nie dotyczy.
Templates i pveam – fundament deploy
Template LXC to tarball z pełnym rootfs dystrybucji. Proxmox VE trzyma je w /var/lib/vz/template/cache/, a narzędzie pveam pobiera je z oficjalnego indeksu. Od PVE 9.1 (listopad 2025) dostępne są też OCI images jako tech preview.
Jeśli struktura katalogów Linuksa jest dla Ciebie nowa, zajrzyj do poradnika FHS – wyjaśnia dlaczego templates trafiają do /var/lib a nie do /opt czy /usr.
Podstawowe komendy:
pveam update– odświeża indeks dostępnych templatespveam available --section system– lista dystrybucjipveam download local debian-12-standard_12.7-1_amd64.tar.zst– pobraniepveam list local– co już mamy lokalnie
Dostępne dystrybucje w 2026: Alpine 3.20-3.22, AlmaLinux 9/10, Debian 11/12/13, Fedora 41/42, openSUSE Leap 15.6/16.0, Rocky 9, Ubuntu 20.04/22.04/24.04/25.10/26.04. Rozmiary bywają zaskakujące – Alpine 3.19 to 2,84 MB, Debian 12 standard 120 MB, Ubuntu 24.04 około 135 MB.
TurnKey Linux – gotowe appliance
TurnKey Linux dostarcza ponad 100 preconfigured obrazów: Nextcloud, GitLab, Gitea, WordPress, Odoo, media servery. Aktualna wersja stabilna to v18.0 oparta na Debian 12. Core około 110 MB, pełny appliance (np. Nextcloud) około 700 MB. Pobierasz tak samo przez pveam.
OCI images jako LXC – nowość PVE 9.1
Listopadowy release PVE 9.1 dodał możliwość pobierania obrazów OCI (Docker Hub, Quay.io, GHCR) bezpośrednio jako templates LXC. W GUI pojawiło się „Pull from OCI Registry”. Stack konwertuje image na format LXC. To tech preview – w produkcji bym jeszcze poczekał, ale dla homelabu otwiera ciekawe możliwości.
Pierwszy kontener krok po kroku
W Proxmox VE 9.1 utworzenie kontenera to osiem ekranów kreatora w GUI lub jedna komenda pct create w CLI. Poniżej pokazuję obie ścieżki – wybierz tę, która pasuje do Twojego przepływu.
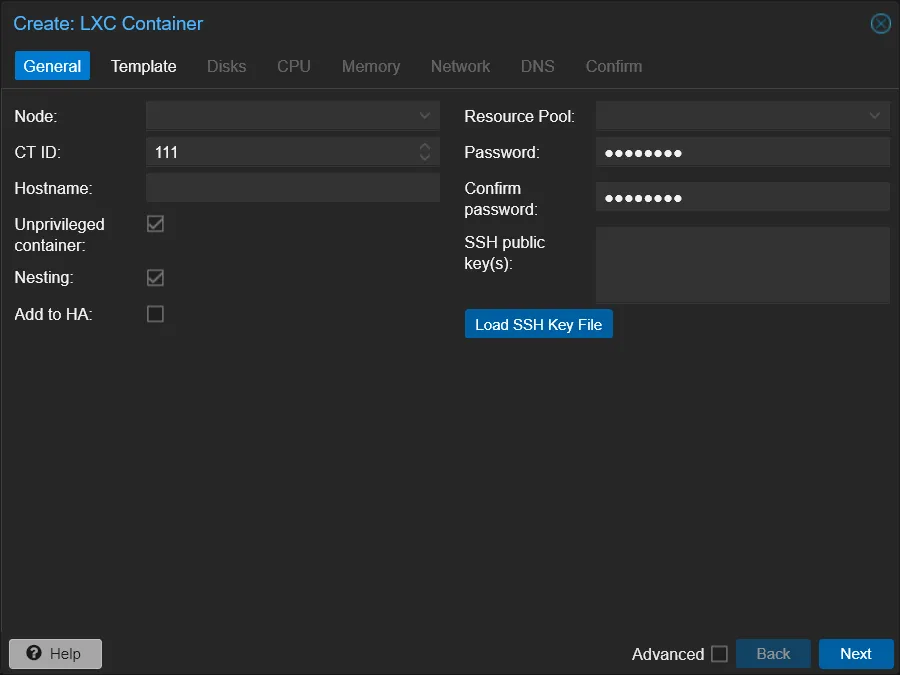
Ścieżka GUI
- General – Node, CT ID (np. 100), Hostname (web01), hasło lub SSH key, checkbox Unprivileged (zostaw zaznaczony), Nesting (zaznacz jeśli planujesz Dockera w środku)
- Template – Storage:
local, Template:debian-12-standard_12.7-1_amd64.tar.zst - Disks – Storage:
local-lvm, Disk size: 8 GiB (pamiętaj, potem łatwo rozszerzyć, trudno zmniejszyć) - CPU – Cores: 2, CPU limit: 0 (bez limitu), CPU units: 100 (default)
- Memory – Memory: 1024 MiB, Swap: 512 MiB
- Network – Bridge: vmbr0, IPv4: DHCP lub static
- DNS – domyślnie dziedziczy z hosta; dla custom –
1.1.1.1i search domain - Confirm – checkbox „Start after created”, klik Finish
Ścieżka CLI – jedna komenda
pct create 100 local:vztmpl/debian-12-standard_12.7-1_amd64.tar.zst \
--hostname web01 \
--cores 2 --memory 1024 --swap 512 \
--net0 name=eth0,bridge=vmbr0,ip=dhcp \
--storage local-lvm --rootfs local-lvm:8 \
--unprivileged 1 \
--features nesting=1,keyctl=1 \
--ssh-public-keys /root/.ssh/id_ed25519.pub \
--onboot 1 --start 1 \
--timezone Europe/WarsawPo kilku sekundach masz działający kontener. Wchodzisz przez pct enter 100 lub SSH na IP z pct exec 100 -- ip -4 addr show eth0.
Zarządzanie i zaawansowane możliwości
Narzędzie pct pokrywa cały cykl życia kontenera – od startu przez zmianę zasobów na żywo po snapshoty i migracje. Większość operacji to jedna komenda, a hotplug działa dla RAM, swap, cores i sieci bez restartu.
pct w codziennej pracy
pct list,pct status 100– co działapct start 100,pct shutdown 100,pct stop 100 --force– lifecyclepct set 100 --memory 2048– hotplug RAM bez restartupct resize 100 rootfs +5G– rozszerzenie dysku (tylko w górę!)pct snapshot 100 before-upgrade– snapshot (wymaga ZFS/BTRFS/LVM-thin)pct clone 100 101 --full– klonowaniepct migrate 100 node2 --restart– jedyny sposób migracji LXC między nodami
Bind mounts i nesting dla Dockera
Bind mount montuje katalog hosta do kontenera – zero overhead, żywe dane. Komenda: pct set 100 -mp0 /mnt/bindmounts/shared,mp=/shared. Zgodnie ze standardem FHS katalog /mnt jest przeznaczony właśnie na takie montowania.
Uwaga z wiki Proxmox: „Never bind mount system directories like /, /var or /etc into a container – this poses a great security risk.” Bind mounts nie są też backupowane przez vzdump – musisz je obsłużyć osobno.
Docker wewnątrz LXC wymaga dwóch flag: features: nesting=1,keyctl=1. Od lxc-pve 6.0.5-2 (patch #7006) Docker w unprivileged LXC działa stabilnie bez hackowania /proc/sys.
Migracja, GPU, backupy
LXC nie wspiera live migration – to twarde ograniczenie wynikające z shared kernel. GPU passthrough do LXC to inny mechanizm niż VFIO w VM: lxc.mount.entry: /dev/dri dev/dri none bind,optional,create=dir plus mapowanie cgroup devices. Sterownik zostaje na hoście, wiele kontenerów może współdzielić jedną kartę (idealne dla Plex, Jellyfin, Frigate). Backup przez vzdump obsługuje tryby stop, suspend i snapshot – ten ostatni daje zero downtime przy storage z CoW.
Siedem pułapek, które łapią początkujących
Te błędy widzę regularnie na forum Proxmox i w homelabach znajomych. Większość kosztuje godzinę debugowania, a unika się ich jednym checkboxem lub flagą w pct create.
- Privileged kontener z bind mountem hosta – root w CT = root na hoście dla tego mountpointu. Exploit w aplikacji = pełny dostęp do danych hosta.
- Brak swap przy dużym memory limit – cgroups v2 traktuje RAM i swap oddzielnie. Spike pamięci bez swap = natychmiastowy OOM kill.
- Docker bez
nesting=1,keyctl=1– dostaniesz „operation not permitted” przy pierwszymdocker run. - Template sprzed kilku miesięcy – pierwszy
apt update && apt upgradeciągnie setki MB. Pobierz świeży template raz na kwartał. - Pomyłka bridge vmbr0 vs vmbr1 – wystawienie kontenera na publiczny LAN zamiast internal. Zawsze sprawdzaj
brctl showlub konfigurację sieci w GUI. - Zły rozmiar dysku na start –
pct resizedziała tylko w górę. Zmniejszenie = backup, destroy, restore z nową konfiguracją. - CentOS 7 lub Ubuntu 16.04 w PVE 9.x – nie startują, bo systemd <231 nie obsługuje cgroups v2. Migracja do nowszej dystrybucji lub downgrade do PVE 8.4.
Podsumowanie
Kontenery LXC w Proxmox VE 2026 to najlepsza technologia dla 80% typowych workloadów homelabu i małej produkcji – gdzie nie potrzebujesz Windows, pełnej izolacji ani live migration. Dają gęstość 100+ instancji per node, start w sekundy i overhead rzędu 10-100 MB RAM. Resztę zostaw dla VM.
Kluczowe wnioski:
- LXC dzieli kernel z hostem – dlatego jest lekkie, ale ograniczone do Linuksa
- Unprivileged to domyśl i jedyna sensowna opcja poza NFS/FUSE/legacy
- Overhead RAM to 10-100 MB vs 512 MB – 1 GB dla VM, CPU praktycznie zero
- Brak live migration – tylko
pct migrate --restartz downtime kilku sekund - Docker w LXC działa od lxc-pve 6.0.5-2, ale produkcyjnie wolę Docker w dedykowanej VM
Utwórz pierwszy kontener teraz – pct create zajmuje 30 sekund, a daje lepsze zrozumienie technologii niż godzina czytania.
FAQ
Czym LXC różni się od Dockera?
LXC to kontener systemowy – zachowuje się jak lekka VM z systemd, SSH i wieloma usługami, utrzymujący stan między restartami. Docker to kontener aplikacyjny – jeden proces per kontener, ephemeral, zorientowany na microservices. W Proxmox LXC to natywny sposób uruchamiania izolowanych Linuxów, Docker najlepiej postawić w VM albo w LXC z nesting=1,keyctl=1.
Czy w LXC można uruchomić Windows?
Nie. Kontenery LXC dzielą kernel hosta, który w Proxmox VE jest Linuksem – więc uruchomisz tylko dystrybucje Linuksa. Dla Windows, FreeBSD, OPNsense czy TrueNAS Core musisz użyć maszyny wirtualnej KVM. To fundamentalne ograniczenie architektury, nie brak feature’a.
Ile RAM-u potrzebuje kontener LXC?
Zależnie od dystrybucji: Alpine idle 10-50 MB, Debian idle około 100 MB, typowa produkcja z jedną aplikacją 100-500 MB. Proxmox VE domyślnie przydziela 512 MB RAM i 512 MB swap, minimum to 16 MB. Dla porównania analogiczna VM z Linuksem potrzebuje 512 MB – 1 GB tylko na guest kernel i cache.
Czy LXC wspiera live migration między nodami?
Nie. Oficjalna dokumentacja Proxmox stwierdza wprost: „Running containers cannot be live-migrated due to technical limitations.” Wspierana jest tylko migracja restart-based: pct migrate 100 node2 --restart. Z replikacją ZFS downtime może być rzędu kilku sekund. Jeśli potrzebujesz zero-downtime migration – wybierz KVM VM.
Privileged czy unprivileged – co wybrać dla domowego serwera?
Zawsze unprivileged, chyba że masz bardzo konkretny powód: NFS/CIFS mount z poziomu kontenera, FUSE filesystem, legacy aplikacja wymagająca CAP_SYS_ADMIN. Oficjalna wiki Proxmox: „The LXC team considers [privileged containers] as unsafe.” Unprivileged jest domyślnym wyborem w GUI od PVE 4.4 z grudnia 2016 i przez ostatnie 10 lat udowodnił bezpieczeństwo w produkcji.